Tìm hiểu AE for feature extraction
Tìm hiểu autoencoder
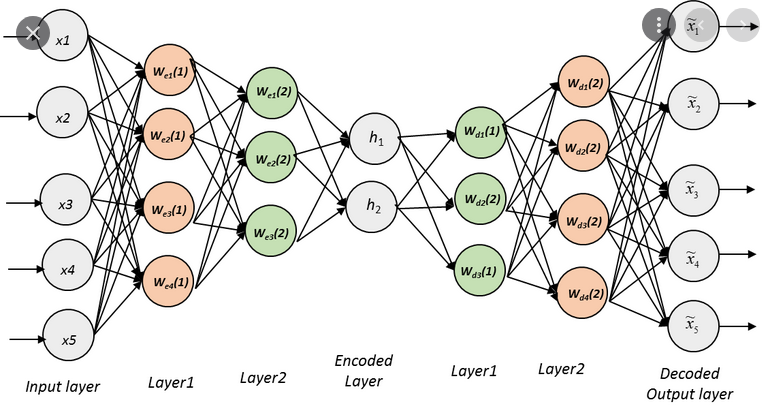
Kiến trúc cơ bản của AutoEncoder
Code mẫu ví dụ
Load thư viện
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sklearn.datasets import make_classification
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from keras.models import load_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import LeakyReLU
from keras.layers import BatchNormalization
from keras.utils import plot_model
import matplotlib.pyplot as plt
Load datasets
1
2
3
4
#Dataset
X, y = make_classification(n_samples = 1000, n_features = 100, n_informative = 10, n_redundant=90, random_state = 1 , n_classes = 5)
print('Shape', X.shape)
X
Scale datasets
1
2
3
4
5
6
7
8
9
# Train test Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.33, random_state = 1)
#Scale data
t = MinMaxScaler()
t.fit(X_train)
X_train = t.transform(X_train)
X_test = t.transform(X_test)
X_train.shape, X_test.shape
shape data
((670, 100), (330, 100))
Encoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
visible = Input(shape = (n_inputs,))
#Define Encoder
#level 1
e = Dense(n_inputs*2)(visible) # e = encoder
e = BatchNormalization()(e)
e = LeakyReLU()(e)
# level 2
e = Dense(n_inputs)(e)
e = BatchNormalization()(e)
e = LeakyReLU()(e)
#Bottleneck
n_bottleneck = round(float(n_inputs)/2.0)
bottleneck = Dense(n_bottleneck)(e)
# Define Decoder
#level 1
d = Dense(n_inputs)(bottleneck) # d = dencoder
d = BatchNormalization()(d)
d = LeakyReLU()(d)
#level 2
d = Dense(n_inputs*2)(d) # d = dencoder
d = BatchNormalization()(d)
d = LeakyReLU()(d)
#Output layer
output = Dense(n_inputs, activation = 'linear')(d)
#Define autoencoder model
model = Model(inputs = visible, outputs = output)
#compile autoencoder
model.compile(optimizer = 'adam', loss = 'mse')
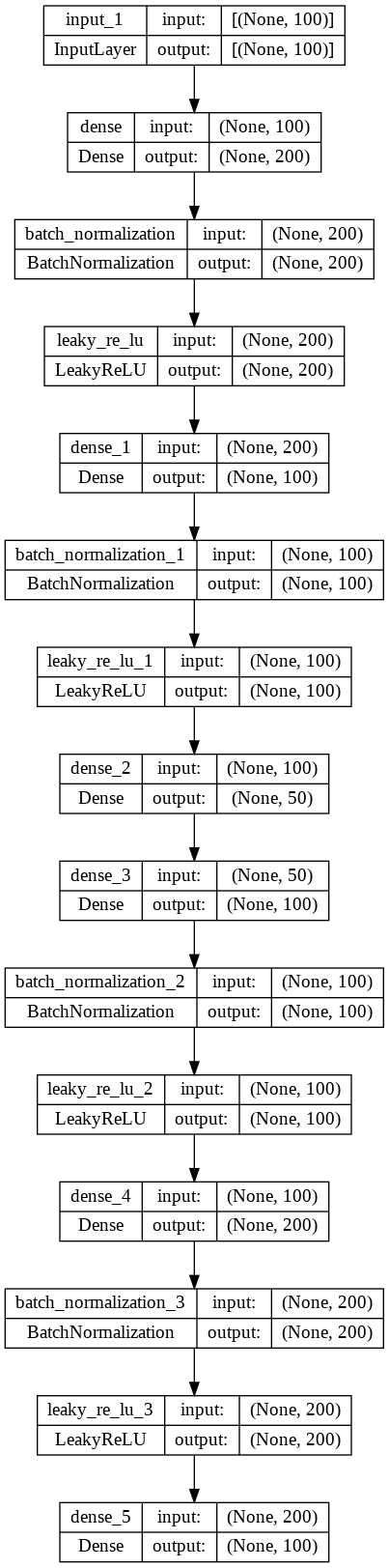
Plot model
1
plot_model(model, 'autoencoder_compress.png', show_shapes = True)
fit model
1
2
# Fit the autoencoder model to reconstruct input
history = model.fit(X_train, X_train, epochs = 200, batch_size = 16, verbose = 2, validation_data = (X_test,X_test))
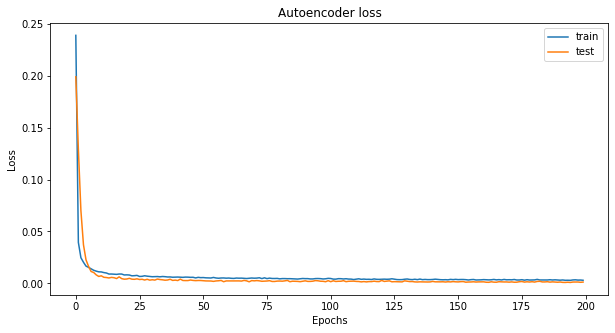
plot loss
1
2
3
4
5
6
7
8
9
10
#Plot Loss
fig, ax = plt.subplots(figsize=(10,5))
plt.plot(history.history['loss'], label = 'train')
plt.plot(history.history['val_loss'], label = 'test')
plt.title('Autoencoder loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.savefig('Autoencoderloss.png')
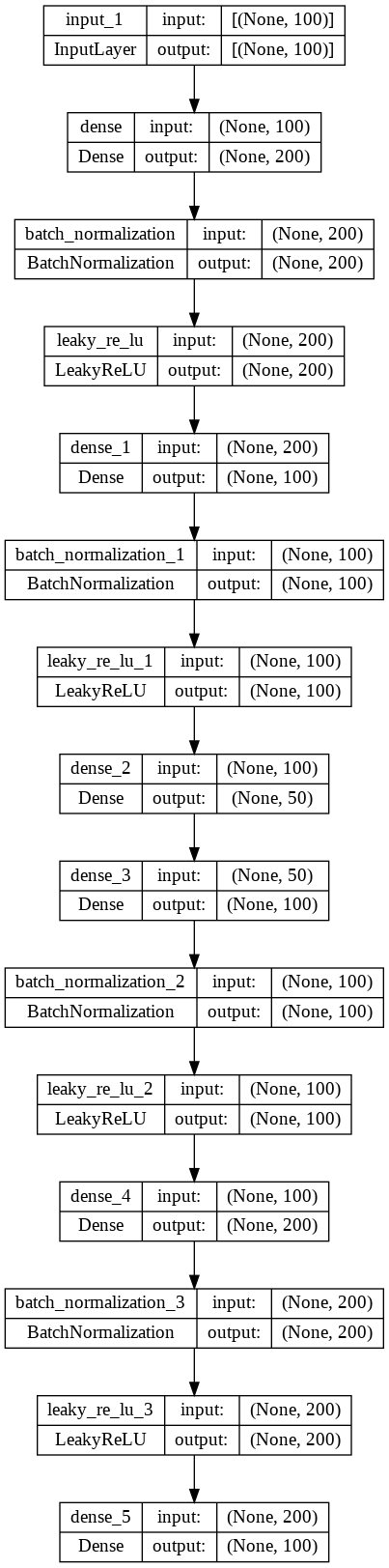
Define an encoder model without the decoder
1
2
3
#Define an encoder model without the decoder
encoder = Model(inputs =visible, outputs = bottleneck)
plot_model(model, 'encoder_compress.png', show_shapes = True)
save model
1
2
# Save model
encoder.save('encoder.h5')
Base logistic Regression
1
2
3
4
5
6
7
8
9
10
11
X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
t = MinMaxScaler()
t.fit(X_train)
X_train = t.transform(X_train)
X_test = t.transform(X_test)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(acc)
Load model
1
2
3
4
5
6
7
8
9
10
11
12
# load the model from file
encoder = load_model('encoder.h5')
# encode the data
X_train_encode = encoder.predict(X_train)
X_test_encode = encoder.predict(X_test)
model_encode = LogisticRegression()
# fit the model on the training set
model_encode.fit(X_train_encode, y_train)
# make predictions on the test set
y_pred_encode = model_encode.predict(X_test_encode)
predict model
1
2
3
4
5
acc_encode = accuracy_score(y_test, y_pred_encode)
print(acc_encode)
print('Accuracy LogisticRegression Simple: {}'.format(acc))
print('Accuracy LogisticRegression With Autoencoder: {}'.format(acc_encode))
Link tham khảo
Tài liệu tham khảo
Machine learning cơ bản
Hết.