Pandas tips cool part 2
Một số tricks cơ bản trong pandas
Import thư viện và load một số dữ liệu để thực hiện thao tác
1
2
3
4
5
6
7
8
9
10
11
import pandas as pd
import numpy as np
drinks = pd.read_csv('https://raw.githubusercontent.com/dophuchao/dophuchao.github.io/master/data/drinks.csv')
movies = pd.read_csv('https://raw.githubusercontent.com/dophuchao/dophuchao.github.io/master/data/imdb_1000.csv')
orders = pd.read_csv('https://raw.githubusercontent.com/dophuchao/dophuchao.github.io/master/data/chipotle.tsv', sep='\t')
orders['item_price'] = orders.item_price.str.replace('$', '', regex = True).astype('float64')
stocks = pd.read_csv('https://raw.githubusercontent.com/dophuchao/dophuchao.github.io/master/data/stocks.csv', parse_dates=['Date'])
titanic = pd.read_csv('https://raw.githubusercontent.com/dophuchao/dophuchao.github.io/master/data/titanic_train.csv')
ufo = pd.read_csv('https://raw.githubusercontent.com/dophuchao/dophuchao.github.io/master/data/ufo.csv', parse_dates=['Time'])
1. Show installed version
1
2
#1. show installed version
print(pd.__version__)
2. Create an example dataframe
1
2
3
4
5
6
7
8
#2. create an example dataframe
df = pd.DataFrame(
{
'col one': [100, 200],
'col two': [300, 400]
}
)
df

1
pd.DataFrame(np.random.rand(4, 8))

1
pd.DataFrame(np.random.rand(4, 8), columns = list('abcdefgh'))

3. Rename columns
1
2
3
4
5
6
7
8
df = df.rename({
'col one': 'col_one',
'col two': 'col_two',
}, axis = 'columns')
df.columns = ['col_one', 'col_two']
df.columns = df.columns.str.replace(' ', '_')
df

Add prefix hoặc add suffix
1
2
df.add_prefix('X_')
df.add_suffix('_Y')
4. Reverse row orders
1
drinks.head()

1
drinks.loc[::-1].head()

1
drinks.loc[::-1].reset_index(drop=True).head()

5. Reverse column orders
1
drinks.loc[:, ::-1].head()

6. Select columns by data type
1
drinks.dtypes

1
drinks.select_dtypes(include = 'number').head()

1
drinks.select_dtypes(include = 'object').head()

1
drinks.select_dtypes(include = ['number', 'object', 'category', 'datetime']).head()

1
drinks.select_dtypes(exclude = 'number').head()

7. Convert strings to numbers
1
2
3
4
5
6
7
8
9
# 7. convert strings to numbers
df = pd.DataFrame(
{
'col_one': ['1.1', '2.2', '3.3'],
'col_two': ['4.4', '5.5', '6.6'],
'col_three': ['7.7', '8.8', '-']
}
)
df

1
df.dtypes

1
2
3
4
5
6
df.astype(
{
'col_one': 'float',
'col_two': 'float'
}
).dtypes

1
2
3
pd.to_numeric(df.col_three, errors = 'coerce')
pd.to_numeric(df.col_three, errors = 'coerce').fillna(0)
df = df.apply(pd.to_numeric, errors = 'coerce').fillna(0)

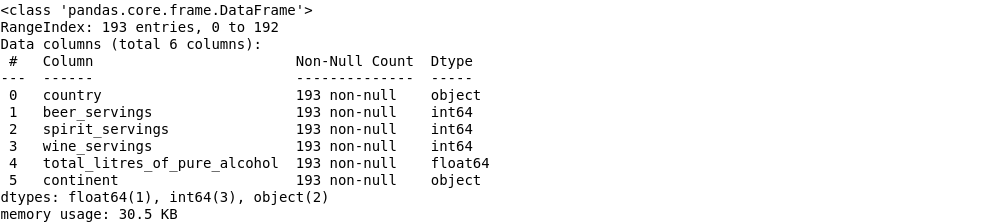
8. Reduce dataframe size
1
drinks.info(memory_usage = 'deep')
1
2
3
cols = ['beer_servings', 'continent']
small_drinks = pd.read_csv('https://raw.githubusercontent.com/dophuchao/dophuchao.github.io/master/data/drinks.csv', usecols = cols)
small_drinks.info(memory_usage = 'deep')

1
2
3
dtypes = {'continent': 'category'}
small_drinks = pd.read_csv('https://raw.githubusercontent.com/dophuchao/dophuchao.github.io/master/data/drinks.csv', usecols = cols, dtype = dtypes)
small_drinks.info(memory_usage = 'deep')

9. Split a dataframe into two random subsets
1
2
3
4
movies_1 = movies.sample(frac = 0.75, random_state = 1234)
movies_2 = movies.drop(movies_1.index)
movies_1.index.sort_values()
movies_2.index.sort_values()
10. Filter a dataframe by multiple categories
1
movies.head()

1
movies.genre.unique()

1
2
3
movies[
(movies.genre == 'Action') | (movies.genre == 'Drama') | (movies.genre == 'Western')
].head()

1
2
3
movies[movies.genre.isin(
['Action', 'Drama', 'Western']
)].head()

1
2
3
movies[~movies.genre.isin(
['Action', 'Drama', 'Western']
)].head()

11. Filter a dataframe by largest categories
1
2
counts = movies.genre.value_counts()
counts

1
counts.nlargest(3)

1
2
3
movies[
movies.genre.isin(counts.nlargest(3).index)
].head()

12. Handle missing values
1
2
3
4
5
ufo.head()
ufo.isna().sum()
ufo.isna().mean()
ufo.dropna(axis='columns').head()
ufo.dropna(thresh=len(ufo) * 0.9, axis = 'columns').head()





Link tham khảo
Tài liệu tham khảo
Machine learning cơ bản
Hết.